
2024知到答案 大数据分析与应用综合实训(厦门南洋职业学院) 最新智慧树满分章节测试答案
绪论 单元测试
1、单选题:
大数据分析与应用综合实训这门课程,是为( )专业的学生准备的实训课程。
选项:
A:人工智能技术应用
B:软件技术
C:云计算技术应用
D:大数据技术
答案: 【大数据技术】
2、多选题:
大数据分析工程项目包含的流程有( )。
选项:
A:数据预处理
B:数据获取
C:数据分析
D:数据可视化
答案: 【数据预处理;
数据获取;
数据分析;
数据可视化】
3、多选题:
作为高等职业教育专科 “大数据技术”专业的学生,需要学习专业基础课程有( )。
选项:
A:数据可视化技术与应用、数据挖掘应用、大数据平台部署与运维
B:程序设计基础(JAVA)、Python编程基础、数据库技术
C:数据采集技术、数据预处理技术、大数据分析技术应用
D:计算机网络技术、Web 前端技术基础、Linux 操作系统
答案: 【程序设计基础(JAVA)、Python编程基础、数据库技术;
计算机网络技术、Web 前端技术基础、Linux 操作系统】
4、多选题:
作为高等职业教育专科 “大数据技术”专业的学生,需要学习专业核心课程有( )。
选项:
A:数据可视化技术与应用、数据挖掘应用、大数据平台部署与运维
B:程序设计基础(JAVA)、Python编程基础、数据库技术
C:计算机网络技术、Web 前端技术基础、Linux 操作系统
D:数据采集技术、数据预处理技术、大数据分析技术应用
答案: 【数据可视化技术与应用、数据挖掘应用、大数据平台部署与运维;
数据采集技术、数据预处理技术、大数据分析技术应用】
5、多选题:
课程要求在教师的指导下,完成5个项目的实操任务。通过学习,达到以下哪些知识目标、能力目标和素质目标?( )
选项:
A:熟悉大数据分析项目的全过程,包括需求分析、平台部署、数据获取、数据清洗、数据分析、数据可视化、总结和应用等一系列流程,具有一定的大数据分析项目的实施和管理能力。
B:掌握大数据工程项目开发框架,具有项目整合开发的能力。
C:掌握Hadoop大数据相关组件的知识,掌握数据获取、数据清洗与分析、大数据可视化的相关知识。
D:具有勤劳务实、敢于担当、严谨认真、精益求精的职业精神;关注细节、检错纠错、深入钻研、开拓创新的职业素养。
答案: 【熟悉大数据分析项目的全过程,包括需求分析、平台部署、数据获取、数据清洗、数据分析、数据可视化、总结和应用等一系列流程,具有一定的大数据分析项目的实施和管理能力。;
掌握大数据工程项目开发框架,具有项目整合开发的能力。;
掌握Hadoop大数据相关组件的知识,掌握数据获取、数据清洗与分析、大数据可视化的相关知识。;
具有勤劳务实、敢于担当、严谨认真、精益求精的职业精神;关注细节、检错纠错、深入钻研、开拓创新的职业素养。】
6、单选题:
学习大数据分析与应用综合实训这门课程,最重要的学习方法是( )。
选项:
A:研究理论
B:动手实操
C:阅读文献
D:摘抄笔记
答案: 【动手实操】
第一章 单元测试
1、单选题:
在环境搭建时,需要安装VMare虚拟机软件,并设置哪一张网卡的IP地址?( )
选项:
A:VMnet1
B:VMnet2
C:VMnet8
D:VMnet0
答案: 【VMnet8】
2、单选题:
抗病毒药物筛选的工程实践中,用Navicat查看test数据库的medicine03表,哪一个字段表示处置?( )
选项:
A:treatment_status
B:disposal
C:preliminary_diagnosis
D:return_visit_result
答案: 【disposal】
3、多选题:
用pymysql.connect方法连接MySQL,需要输入的参数有哪些?( )
选项:
A:主机名或IP地址
B:数据库名称
C:字符集
D:用户名和密码
答案: 【主机名或IP地址;
数据库名称;
字符集;
用户名和密码】
4、单选题:
pandas的apply方法与匿名函数结合,应用非常灵活,如果设置参数axis=1,表示( )。
选项:
A:单元格变换
B:不确定
C:列变换
D:行变换
答案: 【行变换】
5、单选题:
Logistics回归方程中的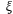 ,表示( )。
,表示( )。
选项:
A:误差项
B:2值化变量
C:概率
D:常数项
答案: 【误差项】
6、单选题:
求解Logistics回归方程中系数,使用( )。
选项:
A:估计法
B:交替最小二乘法
C:拟牛顿法
D:极大似然法
答案: 【极大似然法】
7、单选题:
抗病毒药物筛选的工程实践中,列出回归方程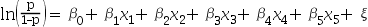 ,哪一个项表示病人的自身提抗力?( )
,哪一个项表示病人的自身提抗力?( )
选项:
A: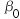
B: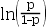
C: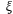
D: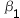
答案: 【】
8、单选题:
对于分类模型的验证,定义假正类数(False Positive , FP),表示( )
选项:
A:模型判断为正,它的判断是正确的,这种情况的统计次数。即被模型预测为正的正样本的数量。
B:模型判断为正,它的判断是错误的,这种情况的统计次数。即被模型预测为正的负样本的数量。
C:模型判断为负,它的判断是错误的,这种情况的统计次数。即被模型预测为负的正样本的数量。
D:模型判断为负,它的判断是正确的,这种情况的统计次数。被模型预测为负的负样本的数量。
答案: 【模型判断为正,它的判断是错误的,这种情况的统计次数。即被模型预测为正的负样本的数量。】
9、单选题:
对于分类模型的验证,定义精确率(precision),precision=TP/(TP+FP),表示( )
选项:
A:实际的正样本中,有多少被正确预测了
B:所有预测结果有多少是正确的
C:实际的负样本中,有多少被预测正确了
D:预测成正样本的结果中,有多少真的是正样本
答案: 【预测成正样本的结果中,有多少真的是正样本】
10、单选题:
利用matplotlib绘图,bar函数可以绘制( )
选项:
A:柱状图
B:饼图
C:折线图
D:散点图
答案: 【柱状图】
第二章 单元测试
1、单选题:
MongoDB的服务器启动命令为( )。
选项:
A:mongo
B:mongoh
C:mongod
D:mongof
答案: 【mongod】
2、单选题:
进入MongoDB客户端的命令是( )。
选项:
A:mongod
B:mongo
C:mongof
D:mongoh
答案: 【mongo】
3、单选题:
本章在数据预处理时,主要使用的数据结构是( )。
选项:
A:Pandas的DataFrame
B:List
C:Numpy的array
D:Dictionary
答案: 【Pandas的DataFrame】
4、单选题:
在sklearn中,支持向量机算法对应的函数为( )
选项:
A:SVC
B:KNeighborsClassifier
C:DecisionTreeClassifier
D:Logistics
答案: 【SVC】
5、多选题:
在语句拆分时,将信息字符串切成一个个单词,并去除停用词。这里的停用词是指( )。
选项:
A:实词
B:符号
C:不使用的词
D:虚词
答案: 【符号;
虚词】
6、多选题:
信息集合中的NAME_AND_CONTENT字段是用文字描述的,计算机在处理文字时,要将其转换为数值化的n维向量,在这一过程中,先后用到的库有( )
选项:
A:nltk
B:numpy
C:jieba
D:gensim
答案: 【nltk;
numpy;
jieba;
gensim】
7、判断题:
在信息集合数值化的程序中,window参数,表示一个词与前后多少词存在相关性。Window越大,关联窗口越大;window越小,关联窗口越小。随着window窗口增大,分类算法性能不断提高,没有上限。( )
选项:
A:对
B:错
答案: 【错】
8、判断题:
在信息集合数值化的程序中,n参数,表示每一条记录转换的数值向量的维度,n越大,计算量就越大。( )
选项:
A:对
B:错
答案: 【对】
9、判断题:
在食品安全信息识别的工程实践中,因为虚警代表着食品安全问题没有被发现,会导致人民的生命健康受到威胁,比漏警引起的危害要大,所以在模型选择上,有意选择虚警率较低的模型。 ( )
选项:
A:错
B:对
答案: 【错】